Design by Constraint - not as useful as people think (#1)
Apr 30, 2011Design by Constraint is a framework pattern used in a number of specifications across healthcare, including a number of high profile standards. It’s a great way to deal with the problem of ensuring semantic consistency in a large information design, but the engineering outcomes are rather less than optimal. Note: This is the first post in a series (probably 3-4 long) that are really a single document explaining design by constraint.
Welcome to “Design by Constraint”** **
Here are some examples of “Design by Constraint” in healthcare:
- HL7 v3 Base methodology
- CDA Implementation Guides (i.e.CCD,C32,IHE profiles)
- CDISC’s BRIDGmodel
- VHIM localisation
- openEHR
- CEN 13606
Because the specification, implementation and engineering differ so widely in these different cases, it’s hard to recognise that the common pattern exists - but it does, and the same issues surface one way or another in each.
Note: For all I know, similar patterns exist outside healthcare. But I’ve not particularly investigated. However DITA and Docbook are in this space. Perhaps I’ll explore that in a later post.
Reference Model
The fundamental notion of design by constraint is easy to summarise:
Define a common information model called the “Reference Model”, that has general applicability, and then describe constraints on it’s use for particular use-cases.
The notion here is that though the use-cases are quite different, the fact that each is connected to an underlying reference model is a great help to implementation because it imposes a common framework along with semantic consistency.
For this reason, the pattern is sometimes called the “reference model pattern”. But sometimes the reference model isn’t known by those terms (“RIM” in HL7 v3, and BRIDG/CDA/VHIM are not called the “reference model” to my knowledge, but that’s exactly how they are treated), so I use the name “Design by Constraint”.
Advantages of Design by Constraint
Before I go on to describe the method in detail from a UML perspective, and detail the attendant problems it creates, I need to underscore the fact that this pattern is a very elegant and powerful way to solve a particularly difficult problem in information model design: semantic consistency.
If a model is designed by a single person, this might not be a problem (if the person is agile, and anal-retentive - an unusual combination). But as the problem size scales, and time passes, the number of participants rises steeply, and the problem of consistency becomes very difficult to manage.
Design by Constraint solves this problem well (though not perfectly).
How Design by Constraint works
- Design a common class model that can be used for everything
- Define meta-patterns associated with it, and rigorously enforce their use
- Define a language for expressing constraints on the model
- Use the language to define constraints for many different use-cases
- **(optional) **Define a transform to convert the constrained use-case model into a new class model
The class model is almost always a UML class diagram. The meta-patterns are usually defined in human language. The language is usually a hybrid language assembled from several different underlying common approaches. Although 5 is labelled as optional, the more time passes, the more likely it is that it will happen. I’ll discuss why this is below.
There’s actually a step #6 that follows logically from the steps above:
- Implementation chaos ensues
The point of these posts is to describe why this is. For the rest of these posts, I’m going to use a rather simple example: a model that describes the commercial arrangements around a restaurant with the following characteristics:
- Restaurants are associated with corporations (many to many)
- Restaurants are associated with people (many to many)
- People are associated with corporations (many to many)
Here’s a simple UML model for this:
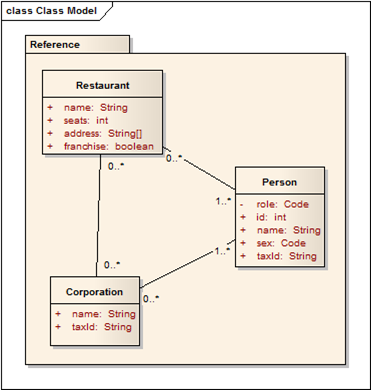
This reference model is intended as a PIM: you create object models in your code, or XML documents and schemas, or database schemas, using your standard approach - whether this is by hand or by some sort of tool assisted approach (of which there are many).
Some quick doco to get us through the rest of the discussion:
- Restaurants have a name, an address, a number of seats, and a flag for whether they are a franchise operation or not. In addition, they must be associated with one or more people and maybe some corporations. (This model does not track the nature of the association)
- Corporations have a name, and maybe a taxId. Each corporation must be associated with at least one person, and maybe some restaurants
- Persons have an id, a name, a code for sex (gender), and a taxId. In addition, a person has a role - a code that defines what kind of person they are
Note: this simple model is far from adequate for any particular application except demonstrating my point.
Constraining the Reference Model
This general reference model is too general for many use cases. For almost all use-cases, in fact, a particular subset of this model is used. But the subset needs to be described, because as soon as the reference model becomes large enough to be functionally useful, there are many different possible ways to represent a use case, and any one using the reference (to make or consume information statements) needs to agree on how it’s done.
Describing the subset is the same as applying a set of constraints to the model. These constraints can be represented using human language constraints, but more structured representations are more amenable to being leveraged by tooling support. Let’s take, as an example, the context of a family business restaurant. Here’s a semi-structured english language statement of constraints: Business: “FamilyBusinessRestaurant”
- franchise property fixed to null
- Address: 3-4 lines, order matters
- No Corporation
- 1Person called “accountant”, 2-6 called “family”
Person: “Accountant”
- role is “ACC”
- taxId is renamed “businessId”
- No Corporation, and sex & id are fixed to null
Person: “Employee”
- role is “EMP”
- id & taxId fixed to null
- No Corporation
It’s worth noting here that the question of what’s a valid constraint differs slightly across the various frameworks. Is it ok to rename fields? Is it ok to fix order? Which data types can be substituted for other data types?
Semantics in the Constraints
One important question is whether the constraining models can contain semantics that are only represented in the constraining model, or whether all the semantics need to come from the underlying reference model. A different way to state this issue is to ask, is it necessary to know and understand the constraining model in order to understand the instance of data, or is it just enough to know the reference model?
In principle, the fundamental concept of “design by constraint” is that you don’t need to understand the constraining model. This allows you to leverage your knowledge of the reference model across multiple contexts without having to understand a particular fine-grained use case. An example of this is with CDA - there is only one document, and you can write a single document viewer that is appropriate to work with every single (proper) CDA document that has ever been written, but there is a profusion of CDA implementation guides describing exactly how information should be structured for particular use cases.
So in principle, the constraining models shouldn’t define semantics that aren’t explicit in the instance of reference model data. Specifically, to use that example above, the constraining model can’t simply say “the first person in a restaurant is the accountant”. Instead, it must say, “the first person has a role code of “ACC”, which means accountant, and this is how you know that the person is an accountant”.
The problem with this is that it’s really difficult to ensure that the constraining model doesn’t introduce new semantics that are not in the underlying data. For example, in the example above, the following semantics are not explicit in the data:
- That a restaurant is a “Family Business Restaurant”. (? whether this matters in some or all contexts, but it is not explicit)
- There’s a subtle interaction in the simple stated constraints between family and employee. There’s an assumption in the constraints that employee = family member, but this might not always be true. Whatever the case, the “family” part is not explicit in the data
(This is more obvious in the data examples that follow)
A general rule is that it’s extremely difficult to ensure that a constraining model doesn’t contain semantics that are not explicit in the data instance. In particular, only thorough human review can determine that the constraining model doesn’t contain implicit semantics.
Note that openEHR varies slightly from the simple pattern here: archetypes are constrained models on the openEHR reference model, but in the very abstract parts of the openEHR reference model (elements), they are allowed and required to define semantics that are only in the archetype. The corollary of this is that you cannot understand the data without knowing the archetype. On the other hand, templates, which are also constraining models, are not allowed to introduce new semantics, so that they can be ignored. They also have the same subtle problems mentioned above.