NullFlavor
May 17, 2011One of the most obvious design features of HL7 v3 is that every class and data type includes the property “nullFlavor”, which provides a reason why the data is (if it has a value), missing, incomplete, or an improper value. This post is my tutorial documentation for NullFlavor. Note: The way HL7 uses NullFlavor is quite controversial. I’m not going to discuss the controversy here, and I’d ask my many friends who read this blog and disagree about nullFlavor **not to comment **below. This is just to explain how it’s supposed to work - let’s not complicate matters (I promise to make a post later where everyone can comment to their heart’s content).
Incomplete Data
Incomplete, erroneous and uncertain data is ubiquitous in healthcare. Everywhere you turn, you find poor quality data. There are a number of reasons why incomplete, partial and uncertain data arises. For example:
- Provisional diagnosis is not confirmed yet
- Patient is unconscious, or unwilling to provide information
- Wrong data was entered into the system, which caused some actions. The wrong data must be retained but clearly labeled as wrong
- Actual value is not a allowable value (i.e. the patient has a healthcare problem for which no existing concept is defined)
- The patient had a adverse reaction to something, but it’s not certain what stimulus caused it
Of course, this problem is not unique to healthcare; poor quality data can be found in all industries, especially in the enormous piles of existing data that cannot be improved. However there are a few things that distinguish healthcare in this respect:
-
Care – and the associated clinical processes – will go on whether the information is good, available or not
-
In most cases, the logical response to poor data is to improve the business processes, but because of the previous point, this is often not possible in healthcare (nor does it help with existing data, of course)
So when it comes to healthcare interoperability, we are interested in both the degree to which data is missing, incomplete, and/or erroneous, and also why. These three categories represent very different aspects of data unreliability, but they have overlapping impacts on the data itself.
Incomplete or erroneous data arises in many different contexts. For instance, care may be provided to unconscious unidentified patients, or patients may refuse to provide a variety of different pieces of information. In addition, clinical processes always occur in the absence of some information; the missing information may be slowly filled in, or may never be acquired (e.g. on the basis that the benefit of acquiring the information doesn’t justify the cost). There’s a wide variety of other clinical reasons. There are also some administrative and infrastructural issues as well. For instance, access to a piece of information may be denied due to security/privacy reasons, or the record may have been lost due to some accident or confusion, or the actual value is not a proper value in the given context. Sometimes data is lost or damaged by some transfer error, usually when information is transferred to the wrong patient, though there are many other kinds of transfer errors and other reasons for erroneous data (and much work on this matter). In spite of much effort, these errors have only been reduced, not eliminated, and they occasionally lead to wrong decisions being made about how to care about the patients. Because this can happen, wrong data needs to be preserved in the record, but clearly labeled as erroneous data. On the other hand, real actions may have been taken as a consequence of the wrong data. Though the grounds for the action may have been erroneous, the fact of the action and its consequences are not erroneous.
At this point, alert readers will ask, what does “the actual value is not a proper value in this context” mean? This is a concept that arises specifically in the v3 data types, though the problem it represents is ubiquitious. To explain it, we need to establish some definitions:
| Value Domain | The set of possible values that an attribute can have. The possible values are firstly established by the definitions of the data types, and then may be further constrained where the attribute that uses the type is defined, by fixing the values of the meta-attributes, or making other constraints |
| Proper Value | A subset of the value domain, excluding some values that are allowed by the value domain but are considered “improper”, in order to help implementers differentiate between allowable error conditions and non-erroneous data. The data types defines an “improper” value as any value that has a nullFlavor. |
| Actual Value | The correct value for the attribute. While the value may not be known, that doesn’t mean that there is no actual value. |
| Represented Value | The value as shown in the instance of the data type. |
Of course, the optimal case is that the represented value is the same as the actual value. However for a variety of reasons, this isn’t always possible. For instance, if the value is not known, the represented value has some kind of nullFlavor, but the actual value is (probably) not. (There’s also an advanced use case: In some cases, the instance may provide enough information to allow the reader to calculate the actual value based on information that the reader of the instance knows - most often used for prescriptions, where the actual value of the prescription depends on body mass or some other biophysical value).
Sometimes, if the actual value isn’t a proper value, there is a problem with the definition of the proper values, which can and does happen. A typical example is where a concept reference allows a small set of concepts to be referenced, and the correct reference is not in the small set. Another example is “trace detected” which is a common laboratory measurement result, and “water to 100mL” which is found in formulations. There’s multiple different perspectives from which to judge what is a “proper value”; in appropriate contexts, these are proper values in a clinical sense, but here the perspective is an informational one: these values are usually measurements (a number/unit pair), but “trace detected” is not a measurement.
These definitions are specific to the HL7 data types, but the concepts apply in any interoperability context: the notions of value domain, proper value, actual value and represented value arise from the problems that interoperability is trying to solve, though there is wide variation in how the problems are solved.
Handling Incomplete Data
The first question with regard to handling incomplete or partial data is the general framework approach: should it be done by exception, or as a matter of infrastructure?
In the by exception approach, whenever an element is identified that may be unknown, or have some unexpected or improper value, a specific design element is added to the model to cater for this, like this: 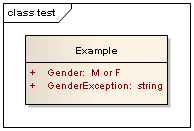
In this case, the Example class has a Gender, with the human genders M and F as possibilities. In 99.9% of cases, the gender of a patient will fall into these two categories. But not all; there are several reasons why a patient may not be either male or female:
- The information is not available
- The patient is a newborn with a genetic error, sexually ambiguous, and the clinician and parents have not (yet) chosen what gender will be assigned
- The patient is undergoing gender reassignment treatment
- In somesocial contexts, there areother possibilitiesthan male and female
When these circumstances are encountered, the Gender attribute would be left as null (which requires that it is allowed to be null), and the GenderException attribute would contain some text explaining why it is null.
The biggest problem with this approach is its unpredictability. It’s really hard for the modelers – the people who build the models above – to account for all the exceptions that arise. This is true whether it’s a standard or just a one off project in a local institution – exceptions are often discovered very late in the development cycle. So these Exception attributes are not always present where they may apply. In some cases – perhaps many cases – the presence or absence of the exception field may not be that important. In the case above, if the gender is null, we know it is unknown, whether we know any reason or not. However as the complexity of the element’s data type grows, the potential interaction between the two attributes grows, and the presence or absence of the exception attribute becomes more important – particularly when both are populated.
Another problem with this “by exception” approach is that handling these cases on an ad-hoc basis produces a variety of different approaches in the exception field – plain text, different sets of codes, some mix of both. The inconsistencies this leads to make it very hard for any of the implementations to take a consistent approach internally when handling the data.
Finally, handling incomplete data with this by exception, ad-hoc based approach tends to produce best-case modeling, where whoever is designing the models takes an optimistic view of the data. People generally work this way: as we learn, we build our internal model of use that is flexible and generally handles failures gracefully, usually by adding additional unexpected communications.
A typical case is with clinical models. Ask any clinician to describe a simple what information is needed to correctly represent and communicate about a simple clinical procedure – say, a blood pressure mechanism – and they’ll automatically tell you that you need systolic and diastolic pressures, posture, and possibly some note about the state of the patient (the longer they think about it, the more they come up with. The openEHR archetype had 19 data elements last time I checked). For 99%+ of blood pressure measurements, the simple 3/4 data element version model works fine. And in a paper form, that’s good enough. Say you created a standard form, with slots for systolic, diastolic, and a series of boxes to tick for posture, with the six most common postures. That’s ok because when patient is a 3 year old child who’s already rather panicky, and gets hysterical when the blood pressure measurement is tried, you’d usually just write some note describing why the blood pressure measurement failed next to the slots on the paper. But computers don’t work like that: if it’s not described in the model, it most likely won’t be possible. Even if it’s possible in some system, it certainly won’t be possible to transfer between systems. So as well as thinking about how things should be, you also have to think about all the ways that they might not be how they should be.
Dates are another great case in point. Most people know their date of birth, or have a designated fictitious date of birth that they use (say, a refugee is assigned one upon being admitted as a citizen of another country if their original data of birth is unknown). And all sorts of payment forms and workflows depend on knowing the age of the patient, so systems very often make date of birth a mandatory field. But some people don’t know their date of birth, or won’t say what it is (maybe unconscious or just not co-operative). So what happens in these cases? Usually, the clerical staff will just “know” that a special date is the “unknown” birth date. Mostly it’s the date 01-01-01, but systems vary. When migrating data between systems, or setting up data interchange, there’s always confusion around these special dates.
One problem here is that by the time you account for all these exceptions, the model will no longer be simple or well designed. Real life is Yuck. And the effect of not catering exceptional data may be to prevent communication altogether. What else can you do – invent a legal value?
For these reasons, a consistent design approach is much preferred when designing models of healthcare. The approach taken in the v3 data types is to handle unknown, incomplete, or unreliable data with a single consistent approach where every value may have a proper value, or a nullFlavor of its own. In practice, this means that we declare a type called “ANY” with an attribute called “nullFlavor”, and all the types derive from ANY so that they have the nullFlavor attribute.
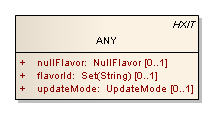
The most important feature of ANY is nullFlavor; I’m going to igore the other attributes here. The nullFlavor attribute is an enumeration which may be null, or have one of the following values:
| 1 | NI | no information | The value is exceptional (missing, omitted, incomplete, improper). |
No information as to the reason for being an exceptional value is provided. This is the most general exceptional value. It is also the default exceptional value |2|INV|Invalid|The value as represented in the instance is not a member of the set of permitted data values in the constrained value domain of a variable |3|OTH|Other|The actual value is not a member of the set of permitted data values in the constrained value domain of a variable. (e.g., concept not provided by required code system) |4|PINF|positive infinity|Positive infinity of numbers |4|NINF|negative infinity|Negative infinity of numbers |3|UNC|Unencoded|No attempt has been made to encode the information correctly but the raw source information is represented (usually in originalText) |3|DER|Derived|An actual value may exist, but it must be derived from the provided information (usually an expression is provided directly) |2|UNK|unknown|A proper value is applicable, but not known |3|ASKU|asked but unknown|Information was sought but not found (e.g., patient was asked but didn’t know) |4|NAV|temporarily unavailable|Information is not available at this time but it is expected that it will be available later |3|NASK|not asked|This information has not been sought (e.g., patient was not asked) |3|QS|sufficient quantity|The specific quantity is not known, but is known to be non-zero and is not specified because it makes up the bulk of the material: ‘Add 10mg of ingredient X, 50mg of ingredient Y, and sufficient quantity of water to 100mL.’ The null flavor would be used to express the quantity of water |3|TRC|trace|The content is greater than zero, but too small to be quantified |2|MSK|masked|There is information on this item available but it has not been provided by the sender due to security, privacy or other reasons. There may be an alternate mechanism for gaining access to this information.
Warning: Using this null flavor does provide information that may be a breach of confidentiality, even though no detail data is provided. Its primary purpose is for those circumstances where it is necessary to inform the receiver that the information does exist without providing any detail |2|NA|not applicable|No proper value is applicable in this context (e.g., last menstrual period for a male)
Null is not Null
There are a number of things to say about this table. The first and most important thing is that “nullFlavor” is not the same as “null”. A “null” pointer is a familiar concept to programmers: a pointer with a value of 0, that points to nothing. By definition, if a value is null, there is nothing else known about the object. This doesn’t apply to nullFlavor (you can tell by the definitions of the enumerations – particularly invalid, other, unencoded, and derived). In such cases, even if nullFlavor has a value, the other attributes of ANY and its descendents may have values (which also follows logically from how they are defined in UML). For example:
<CD nullFlavor="OTH" codeSystem="SNOMED">
<originalText>Burnt Ear</originalText>
</CD>
This is a coded value, with a nullFlavor, and also a codeSystem and an originalText. (In fact, the discussion of “OTH” in the CD section requires a codeSystem attribute to be present if the nullFlavor attribute has a value.)
So if nullFlavor is different to null, why give it such an appallingly confusing name? Well, though nullFlavor is not the same as “null”, the behavior of types with nullFlavors is very similar to null in SQL and OCL. In addition, the data types were defined by HL7, and in the HL7 context, there is string internal continuity between the concept of “null” in the ISO 21090 and earlier HL7 data type definitions. (And also because “ExceptionalValueStatusFlag” is a pig to say – and nullFlavor is a word that used a lot).
For instance, in SQL, given a table like this:
| Key | Name | Count |
| 1 | USA | 0 |
| 2 | Canada | 1 |
| 3 | Australia | Null |
The SQL statement “Select count() from test where count != 0” will return a value of 1, and both the SQL statements “Select count() from test where count = null” and “Select count(*) from test where count != null” return 0. This is because null values are never equal in SQL. Like SQL null values, v3 data types that have a nullFlavor are never equal, even if all other attributes have the same value.
Note that in select situations, values that have a nullFlavor may be known to not equal; for instance, two values with nullFlavor PINF (positive infinity) and NINF (Negative Infinity) are clearly not equal, even if we cannot say that two values that both have nullFlavor PINF are equal. The very specific uses of infinity in healthcare data are discussed in chapter X.
In OCL, null values propagate through an expression. For instance, in the following expression: CD.displayName.language.equal(x), if CD is null, rather than causing a ‘Null Pointer Exception’ or similar, the null value propagates through the expression, and the result will be null, whatever the value of x is. The ISO 21090 data types are expected to work in a similar fashion. For instance, the following notional expression (in some OCL-like language): “CD.displayName.language.equal(x)”, where CD is null, should generate a null value rather than some “Null Pointer Exception” or equivalent.
So it’s important to understand that in v3 contexts, a data value that has a nullFlavor is called “null”, and that this is not the same as “null” in a programming language: a data value with ANY nullFlavor may have any other attribute populated as well (though a lot of combinations wouldn’t make sense). Semantically, null in a programming language sense (or xsi:nil=”true” in an XML context) is the same as a value with nullFlavor=”NI” and no other attributes valued: either simply says, “We have no information, and no idea why we have no information”. In fact, the rule in the previous paragraph about how the null value propagates through an expression is no different to saying that logically, when accessing a property that is null, you treat it as if it existed with a nullFlavor (which exact nullFlavor varies, and is driven by the semantics. For instance, if the data value is not applicable, then it may reasonably be inferred that all the attributes of the data value are also “not applicable” rather than merely having no information about their state; however there is a great deal of ambiguity in this area; the data types do not make any rules about which nullFlavors should be used, only that one generally should be used).
NullFlavor Enumeration
The second thing to say about this table is that all the values of the NullFlavor enumeration are a simple list, the meaning is more complex – as in a proper terminology, some of the enumeration values subsume others in meaning. So while we can say that OTH <> INV, if the question is, is this value “invalid” (is its nullFlavor “INV”), then this is also true if the nullFlavor is OTH, since OTH implies INV. This is a common feature of enumerations in v3 and also found in healthcare more generally. Another common feature in healthcare is the quality of the definitions: they sort of make sense when you first work with them, but the more data coding you do, the harder it becomes to sift through them. Many of the definitions are particularly opaque until the semantics of the other data types are understood. But even after they are understood, ambiguities remain. For instance, exactly when does something become “not applicable” rather than merely “unknown”?
Some of the nullFlavors in the table apply to most contexts in which a data type is used. For instance, it’s easy to see how “unknown” or “not applicable” might be used in most places where a data element could be used, some of them are rather more specific. For instance, it wouldn’t make sense to use positive or negative infinity in any place but where a numerical value is expected. This is a feature of a general solution to the problem of incomplete or partial data: handling all the different cases in a single infrastructure provides consistency in one way at the cost of allowing inconsistency in other ways. As a consequence, v3 makes a number of rules about the contexts in which some of the nullFlavors may be used.
So nullFlavor is a very strong design pattern in v3: every data type carries a nullFlavor, and when you are working with data types you must always check the nullFlavor. Like checking null becomes a reflexive habit when programming in java, checking the nullFlavor must become a reflexive behavior when working with the data types. The consistent approach to incomplete or partial data that nullFlavor represents certainly carries a cost, but the payoff, in terms of consistency and clinical safety, is considerable.
Like all standards, the nullFlavor approach has grown in complexity, and some of the particular nullFlavors reflect weird use cases that normal implementers will not encounter. In general, though you must always check for the presence of nullFlavor, the particular kind of nullFlavor doesn’t really matter in most cases - it’s just another different reason the data is missing, and it doesn’t really matter. When the workflow makes it matter, then it will make sense to check for particular NullFlavors. However there are three general cases where the type of the nullFlavor does matter:
- OTH/UNC on coded values
- TRC/QS/DER on measurements
- PINF and NINF on interval boundaries
Many implementers look at the NullFlavors above (the explanation is certainly long….) and get filled with an urgent desire to simplify it. That makes sense – it’s a typical response to a mature standard, and this part of v3 might be called more “mature” than others. And feel welcome to simplify it – but my advice is to keep the consistency and ubiquity of the nullFlavor approach, however you handle incomplete or partial data.
End Notes:
- All v3 classes have nullFlavor as well. There’s some pretty subtle things about that and I don’t think anyone has ever written it up - I’ll try and get to that