ISO 21090: Underlying design propositions #2
Jul 16, 2011This is a follow up for ISO 21090: Underlying design propositions #1 Mixins
The underlying notional data type definitions on which ISO 21090 is based (the HL7 v3 Abstract Data Types) include several mix-ins, specifically HXIT, URG, and EXPR. Mixins are a strange type: a generic class that extends the parameter class, instead of expressing properties of the type of the parameter class. That’s a hard idea to get your head around; it’s much easier to understand when you express it like this:
mixin
Using mixins like this leads to lovely clean designs. But very few languages can actually implement them. (Eiffel can. Ruby supposedly can. Ada supposedly can). But none of the mainstream implementation technologies can (and I think that’s not merely coincidence). If the architectural design uses mixins, there’s three different bad choices for how mainstream implementations can make them work:
- Create a wrapping type Mixin<T: X> where it has a property base : T
- Create a whole slew of types Mixin_T - bascially pre-coordinate the Mixin type by hand
- Push the attributes of Mixin up to X (the base type for T)
Mixins are also discussed here (in a little bit more detail).
ISO 21090 had a base value proposition: that implementers can take the UML model or the schema, and implement them as is with no fancy shenanigans. So we had to make a choice - one of the three above. We chose option #3 for most of the mixins, and pushed their properties up to X, which in practice means that ANY has the HXIT properties, and QTY has the URG and EXPR properties. This, after all, mapped directly to the actual implementations that existed for the v3 data types at the start of the project (at least, those that people would own up to). Btw, it works too - my data type implementation is code generated from the UML (manually, by keyboard macros, but still generated). Other implementations are code generated from the UML or schema too.
But option #3 doesn’t lead to good theoretical definitions. The mixin derived properties are everywhere, so that they could be used if it was appropriate, but mostly they aren’t relevant or allowed to be used.
To my fascination, the choice to have a practical implementation instead of a theoretically better specification that requires much mucking around to implement particularly angered two VIPs in the healthcare data type world. I understand that, but tough. Again and again we looked at it in committee and chose to have a spec that worked for most implementors.
Design by Condensation
This is a bit harder to explain, but it’s an important plank of the way the data types are defined. It’s a design pattern I’ve never seen discussed anywhere else (though it probably is - there’s a myriad of design patterns out there). (btw. it wasn’t me who invented this one, and it took me many years to come to feel the weight of it’s advantages, where as it’s disadvantages are quickly obvious).
Lets take the measurement related notions as an example. The basic notion is a value with a unit. Sometimes, you might want to track how the data was estimated. Sometimes, you might want to just use some human text instead of or as well as the measurement. (it might say “About 6 foot”, for instance).
Here’s a simple standard O-O model where this is done by adding features in specialist classes.
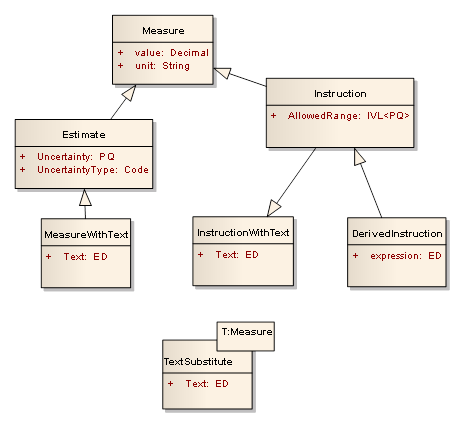
The problem with this is that while it’s evident what this means, it’s not at all evident how this actually works in practice - it’s just fine and dandy when you have a simple measurement, but when do you have to check whether it’s a particular subtype? And there’s also a permutational explosion of classes as different aspects compete to pollute the specialisation tree. In a moderately complicated O-O system, this starts to become pretty difficult to manage (as consequently, there’s all sorts of lore, design patterns etc about how to manage this. The specific model above might or might not be a good one by these patterns, and I don’t want to argue about the specific model in the comments please).
Instead of inventing ever more elegant and difficult to comply with rules about class heirarchies, we could abandon specialisation altogether, and do the design by composition:
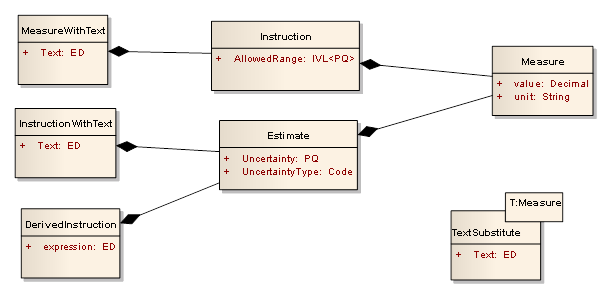
Designing models by composition like this is growing in popularity. It’s just pushing the same complexity around to different places, but it’s less…. ethereal. Large compositional models aren’t hard to understand, just hard to navigate. And they’re still dominated by lots of type testing and casting and various kinds of switch statements.
Instead of either of these two approaches, we could define as few classes as we can get away with:
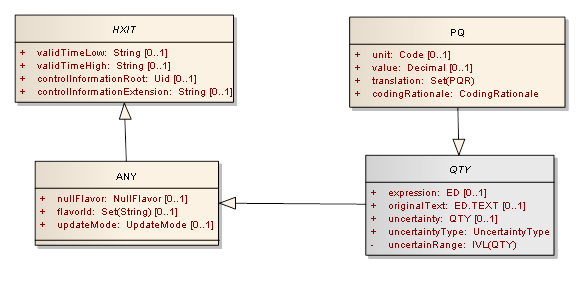
This is what ISO 21090 does (btw, this UML model includes heaps more features than the other ones above). I call it “design by condensation” since we condense everything (it’s just a name I made up, I’m not particularly attached to it).This design pattern has the following features:
- Fewer types (a lot fewer)
- The types themselves are not simple
- But all the logic is done up front
- your investment will pay off with much easier leverage in the long run (there’s that up-front investment again)
- The classes do have more “dangling appendages” - properties that won’t get used very often, and perhaps not at all by particular implementations (See Tom Beale on “FOPP”)
That’s how ISO 21090 works. Is it the right way? I don’t know, but it does have real advantages. But the complexity hasn’t gone away, because you can only move it around (law #2).
Summary
These are the big four design propositions of ISO 21090. I think that understanding these will significantly help people who have to “implement” ISO 21090 in their systems. I put “implement” in quotes because it just means so many different things in different contexts. Which is one reason why ISO 21090 is “for exchange”, not for systems. The problem for system implementors is that this knowledge has never been written down anywhere (until now, now that it’s here), and even knowing this stuff still raises a “so what?”: how would you actually implement ISO 21090 in a system then?
Tom Beale and I are going to co-author a system implementation guide for ISO 12090. It’ll include a different simpler model for the types, and describe how to handle other features, as well as discussing issues like how much to normalise the concept data types. It’s a long time ago we agreed to do this, and I was supposed to do something about it - it will happen one day.