Database schema for my FHIR server
Dec 29, 2012Several implementers have asked me what database I use for my FHIR server, and how I structure the database. I use an SQL database – either MSSQL or MySQL (the cloud server uses MSSQL because Microsoft gives me free licenses via BizSpark). Most of the other implementations use something like MongoDB.
This diagram summarizes the schema that I use:
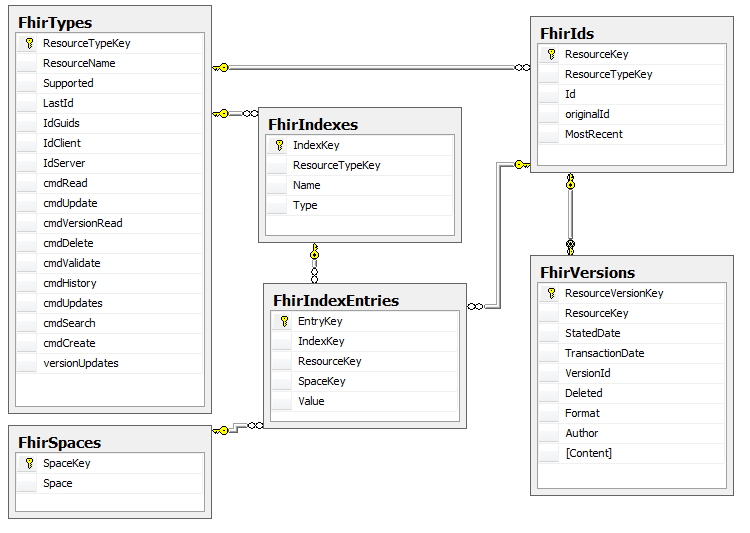
FhirTypes
This table has a row for each defined table type – a name and an internal primary key, along with a set of status fields & flags for how the system supports the type:
- Supported – is the resource even accepted for this server
- LastId – tracks the highest integer id value (if integer ids are being used)
- IdGuids – whether to accept UUIDs logical ids proposed by clients
- IdClient – whether to allow the client to put to a non-existent resource
- IdServer – whether to allow the client to post to the resource type and ask the server to create a resource
- cmd[X] – whether the logical operationis supported or not (note, some operations cannot be supported for some resources, such as search on a binary resource)
- Versionupdates – whether to insist on version aware updates for this resource type
Note that most systems would fix these things globally for all resources, but I’ve found it useful to be able to vary the policy for different resources – it helps during the connectathon testing phase.
FhirIds
A list of known resources with logical ids:
- ResourceKey – primary internal key for resource (not visible externally)
- ResourceTypeKey – type key (reference to FhirTypes)
- Id – logical Id (char(36) as specified in FHIR spec)
- originalId – an extra field my implementation tracks, which is the id a client first provided. This is echoed back to clients so they can link resource by their original id. This is not required by the FHIR spec
- MostRecent – a reference to FhirVersions.ResourceVersionKey, the current version of the resource
FhirVersions
An actual instance of a resource (this table is insert only):
- ResourceVersionKey – internal primary key, not visible externally
- resourceKey – reference to FhirIds.ResourceKey
- StatedDate – the date the client claimed that this resource was created (UTC)
- TransactionDate –the actual date the event occurred (UTC)
- VersionId –the version is assigned when the resource was created
- Deleted – true if this is actually a deletion of the resource
- Format –flag for Xml or Json – the resource is stored as it was received
- Author – from the http layer, who the author was, if known, or just an ip address
- [Content] –the actual resource as a binary (gzipped)
FhirIndexes
List of the indexes that for each resource (derived from the search parameters defined in FHIR spec):
- IndexKey – private internal key
- ResourceTypeKey – reference to FhirTypes.ResourceTypeKey
- Name – Search Parameter name
- Type – type for search parameter from spec. Note that the code that uses the indexes needs to know this value implicitly, so I’ve never actually used this field for anything
FhirIndexEntries
An actual index value. These are populated whenever a resource is inserted into FhirVersions. All existing entries for the resource are deleted, and a new set are inserted by the code processing the resource (I write this code by hand):
- EntryKey – internal primary key, never used anywhere yet
- IndexKey – reference to FhirIndexes.IndexKey – which index this is an entry in
- ResourceKey – reference to FhirIds.ResourceKey
- SpaceKey – reference to FhirSpaces.SpaceKey – see below
- Value – the actual value. Char(128) – search won’t work for values longer than 128 chars
FhirSpaces
For a QToken, the search is actually on a pair of strings – typically a URL with a leaf value. FhirSpaces just normalises the first string – entries are added to this table for each new URI seen. This table exists purely to conserve space, though it may be useful for optimising searches that involve partial matches on QToken spaces, if we decide this is necessary (not supported for now)
This is the schema I use to provide a fully functional and fully flexible FHIR server. It’s not necessary to have a schema like this - you can implement a server that provides direct access to an existing database schema that supports an actual application. That’d be fine and makes sense for many/most implementations, but the functionality provided by such an implementation is going to be limited to that allowed by the application - in particular, providing version history and fully functional searching (especially chained parameters) is going to be challenging with that approach (though it makes sense - you provide support for what makes sense to do as driven by your schema). But since I’m doing a reference implementation, I need to do those things, and hence this schema that provides full support.