FHIR Extensions, the 80/20 rule, DICOM and the LONG tail
Jan 9, 2013As part of FHIR, we have said that resources will only contain the “core” elements, and those not widely used will be delegated to a robust extension mechanism. As a rule of thumb, we’ve talked about using an 80/20 rule - elements should be included in a resource if they are catered for / used by 80% of the implementing systems. This rule of thumb has been quite controversial, even just as a rule of thumb, just used as a guide to help decide what is and isn’t out. One of the big question is 80% of what? And that’s not a simple question, with a simple answer, and it’s not meant to, though it’s one reason why FHIR resources need to have a well defined scope, so that it’s less opaque regarding 80% of what. And even then it’s hard, because it’s extremely difficult to get examples of real world exchanges, let alone a good representative collection, by which you can get even rough statistics.
As part of my preparation for the HL7 Phoenix meeting, I’m giving some thought to what a FHIR resource for RESTful access to DICOM images would look like (this is possible future joint work with NEMA). It’s early days - we don’t know what the scope of RESTful resources would be - study, series, image, plane? But as part of my preparative work, I prepared a scatter plot for the frequency of DICOM elements in my set of sample DICOM images (mostly derived from http://support.dcmtk.org/wiki/dicom/images, but also stuff I’ve collected through commercial use in Australia). Note that it’s easier to collect this for DICOM than for HL7 v2 and CDA documents, since it’s easy to pack messages into files and vice versa (something that I’d like to be true of FHIR, because it really is good for the ecosystem). So we could take this sample set as somewhat illustrative of the situation in health care exchange generally (Note: I have only included data elements in the root of the file, not nested sequences, and the distribution includes manufacturer defined tags as well):
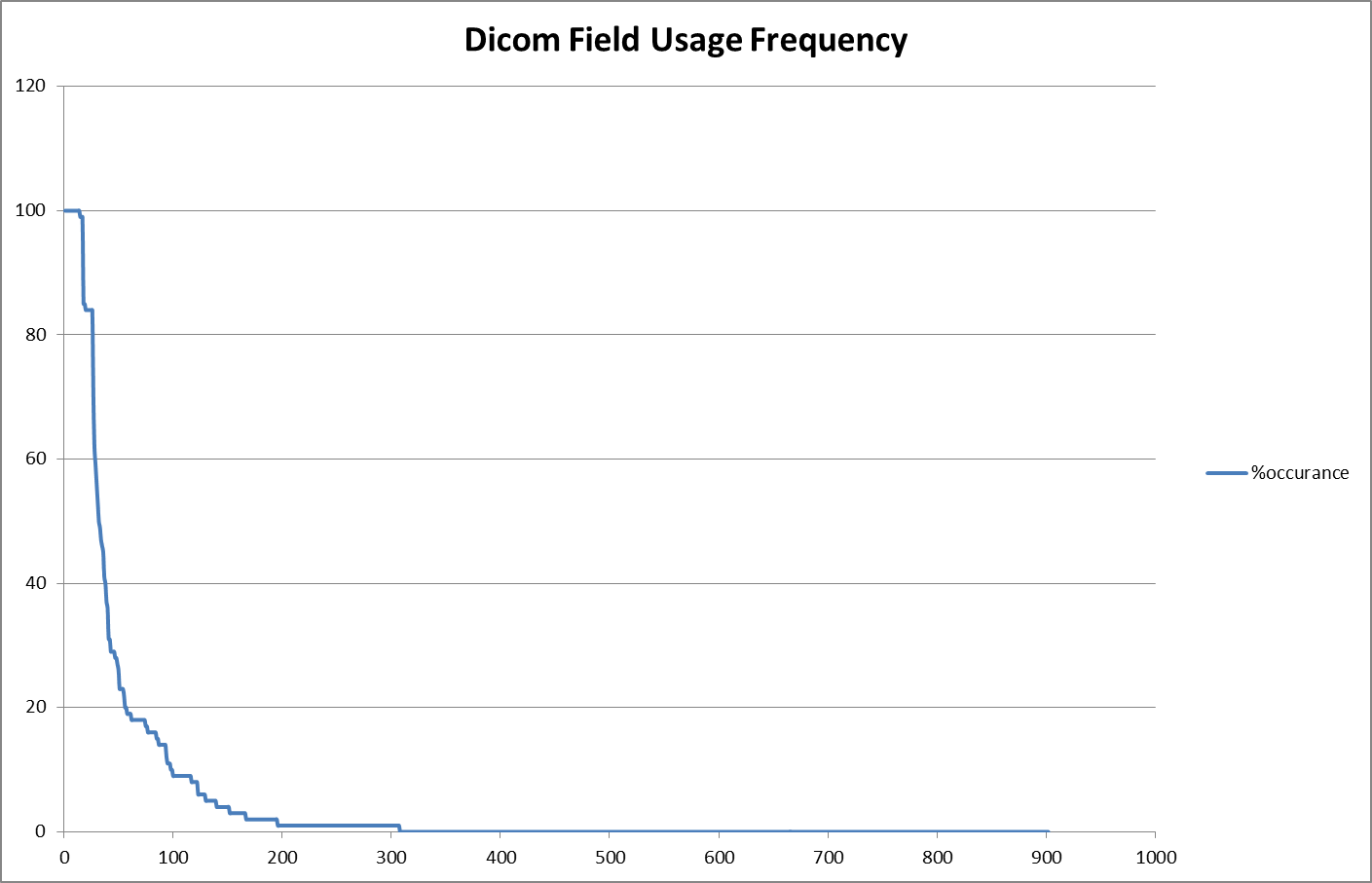
It’s really intriguing to see just how long the tail is - only 30 of 900 different DICOM elements I encountered appeared in >80% of the DICOM images, and about 700 of the 900 appeared in <1% of the images. This tail is longer here than it really is for several reasons:
- it’s a set of DICOM images that cross modalities. One DICOM standard for all modalities, like if you had one HL7 message for all message types (though this set doesn’t include non-image related dicom content such as MPP or structured reports)
- it’s based on the instances, not the systems. The tail will always be longer for instances, since some things only appear a few times, but are always important when they do (i.e. LMP in an image), so they are supported in all/most systems
- it’s based on examples not production images (mostly) - though that might cut both ways
Nevertheless, a few of us that looked at this distribution were surprised by how long the tail is even given these caveats.
Note that the modality is an interesting one: a modality such as MRI is <20% of usage, but obviously important. It needs a whole set of custom data elements to properly describe the image. Perhaps, in a FHIR context, that implies that there might be modality specific resources for further image details? These details lie in front of us. Note that this is a common pattern that crops up in other areas too - such as medications, where 99% of medications are off the shelf retail formulations, but a few specific areas of medicine have highly specific and detailed formulation requirements (i.e. chemotherapy).
I present this primarily to demonstrate the length of the tail. These elements and features often occupy a significant portion of the standard - but a casual reader often can’t judge what to ignore or not until after they’ve read and understood the whole thing. So they add to the cost of implementation, even when they aren’t used. We’re trying to keep the long tail down in FHIR, without denying the functionality that they represent.
As for the FHIR Image resource - the table that underlies this graph will be useful for prioritising what to represent in the resource, but is hardly going to be a final determiner.
Top 30
Since people will no doubt be interested, here’s the top 30 root element list (the 100% are the mandatory elements, so that’s not really surprising):
| 0008,0016 | 100 | (Image Properties/SOP Class UID) |
| 0008,0018 | 100 | (Image Properties/SOP Instance UID) |
| 0008,0020 | 100 | (Image Properties/Study Date) |
| 0008,0030 | 100 | (Image Properties/Study Time) |
| 0008,0050 | 100 | (Image Properties/Accession Number) |
| 0008,0060 | 100 | (Image Properties/Modality) |
| 0008,0070 | 100 | (Image Properties/Manufacturer) |
| 0008,0090 | 100 | (Image Properties/Referring Physician’s Name) |
| 0010,0020 | 100 | (Patient Details/Patient ID) |
| 0020,000D | 100 | (Study Instance Properties/Study Instance UID) |
| 0020,000E | 100 | (Study Instance Properties/Series Instance UID) |
| 0020,0010 | 100 | (Study Instance Properties/Study ID) |
| 0020,0011 | 100 | (Study Instance Properties/Series Number) |
| 0020,0013 | 100 | (Study Instance Properties/Instance Number) |
| 0010,0010 | 99 | (Patient Details/Patient’s Name) |
| 0010,0030 | 99 | (Patient Details/Patient’s Birth Date) |
| 0010,0040 | 99 | (Patient Details/Patient’s Sex) |
| 0028,0010 | 85 | (Sampling Property/Rows) |
| 0028,0011 | 85 | (Sampling Property/Columns) |
| 0028,0002 | 84 | (Sampling Property/Samples per Pixel) |
| 0028,0004 | 84 | (Sampling Property/Photometric Interpretation) |
| 0028,0100 | 84 | (Sampling Property/Bits Allocated) |
| 0028,0101 | 84 | (Sampling Property/Bits Stored) |
| 0028,0102 | 84 | (Sampling Property/High Bit) |
| 0028,0103 | 84 | (Sampling Property/Pixel Representation) |
| 7FE0,0010 | 84 | (Pixel Data/Pixel Data) |
| 0008,1030 | 70 | (Image Properties/Study Description) |
| 0008,103E | 62 | (Image Properties/Series Description) |
| 0008,0008 | 59 | (Image Properties/Image Type) |
| 0020,0020 | 56 | (Study Instance Properties/Patient Orientation) |
| 1 | y | 0008,0016 | 100 | (Image Properties/SOP Class UID) |
| 2 | y | 0008,0018 | 100 | (Image Properties/SOP Instance UID) |
| 3 | y | 0008,0020 | 100 | (Image Properties/Study Date) |
| 4 | y | 0008,0030 | 100 | (Image Properties/Study Time) |
| 5 | y | 0008,0050 | 100 | (Image Properties/Accession Number) |
| 6 | y | 0008,0060 | 100 | (Image Properties/Modality) |
| 7 | y | 0008,0070 | 100 | (Image Properties/Manufacturer) |
| 8 | y | 0008,0090 | 100 | (Image Properties/Referring Physician’s Name) |
| 9 | y | 0010,0020 | 100 | (Patient Details/Patient ID) |
| 10 | y | 0020,000D | 100 | (Study Instance Properties/Study Instance UID) |
| 11 | y | 0020,000E | 100 | (Study Instance Properties/Series Instance UID) |
| 12 | y | 0020,0010 | 100 | (Study Instance Properties/Study ID) |
| 13 | y | 0020,0011 | 100 | (Study Instance Properties/Series Number) |
| 14 | y | 0020,0013 | 100 | (Study Instance Properties/Instance Number) |
| 15 | y (ref) | 0010,0010 | 99 | (Patient Details/Patient’s Name) |
| 16 | y (ref) | 0010,0030 | 99 | (Patient Details/Patient’s Birth Date) |
| 17 | y (ref) | 0010,0040 | 99 | (Patient Details/Patient’s Sex) |
| 18 | y | 0028,0010 | 85 | (Sampling Property/Rows) |
| 19 | y | 0028,0011 | 85 | (Sampling Property/Columns) |
| 20 | y | 0028,0002 | 84 | (Sampling Property/Samples per Pixel) |
| 21 | y | 0028,0004 | 84 | (Sampling Property/Photometric Interpretation) |
| 22 | y | 0028,0100 | 84 | (Sampling Property/Bits Allocated) |
| 23 | y | 0028,0101 | 84 | (Sampling Property/Bits Stored) |
| 24 | y | 0028,0102 | 84 | (Sampling Property/High Bit) |
| 25 | y | 0028,0103 | 84 | (Sampling Property/Pixel Representation) |
| 26 | n/a | 7FE0,0010 | 84 | (Pixel Data/Pixel Data) |
| 27 | 0008,1030 | 70 | (Image Properties/Study Description) | |
| 28 | 0008,103E | 62 | (Image Properties/Series Description) | |
| 29 | 0008,0008 | 59 | (Image Properties/Image Type) | |
| 30 | 0020,0020 | 56 | (Study Instance Properties/Patient Orientation) |