Identifiers in NEHTA Clinical Documents
Feb 9, 2013There’s not a lot of good information around about handling identifiers in CDA documents. I’ve written about it before, but I’m not aware of anything else that’s publicly available. My previous post was “Identifiers in CDA Documents- Reporting Tool” and I really recommend that you read that one first. This post provides advice for how to use identifiers in NEHTA Clinical Document CDAs. In the course of time, this advice will develop into an official NEHTA FAQ, but I’m writing the guts of it here to get comment on it first. In NETHA documents, Acts, Roles and Entities all have an id element, which usually has the following description:

In addition to the id element, some of the roles have an additional set of identifiers hanging off them:
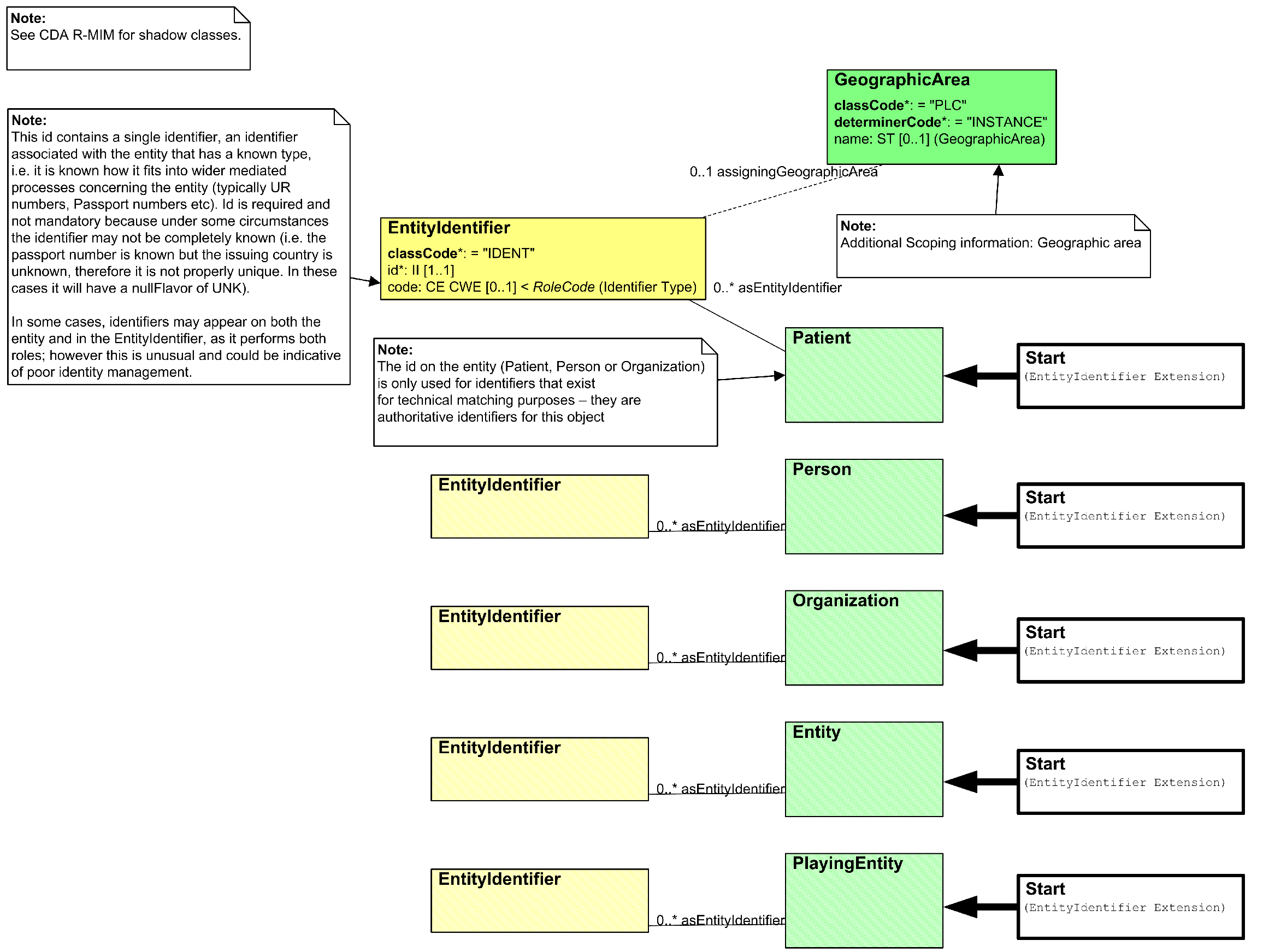
In effect, the specification draws a difference between “technical identifiers” and “real world identifiers”. Real world identifiers – the ones that go in the “EntityIdentifier” class above – are ones that are mapped from the SCS (the logical definition of the document contents), or introduced from local usage such as MRN. Note the definition of the real world identifier: “it is known how it fits into the a wider mediated process concerning the entity”. That kind of leaves the “technical identifier” as the identifier where it isn’t known how it fits into the wider process. This post explains how that identifier element is meant to be used, and the limitations to be aware of when handling it.
The id element is a required element in some places of the CDA document, and not in others. Here’s an example:
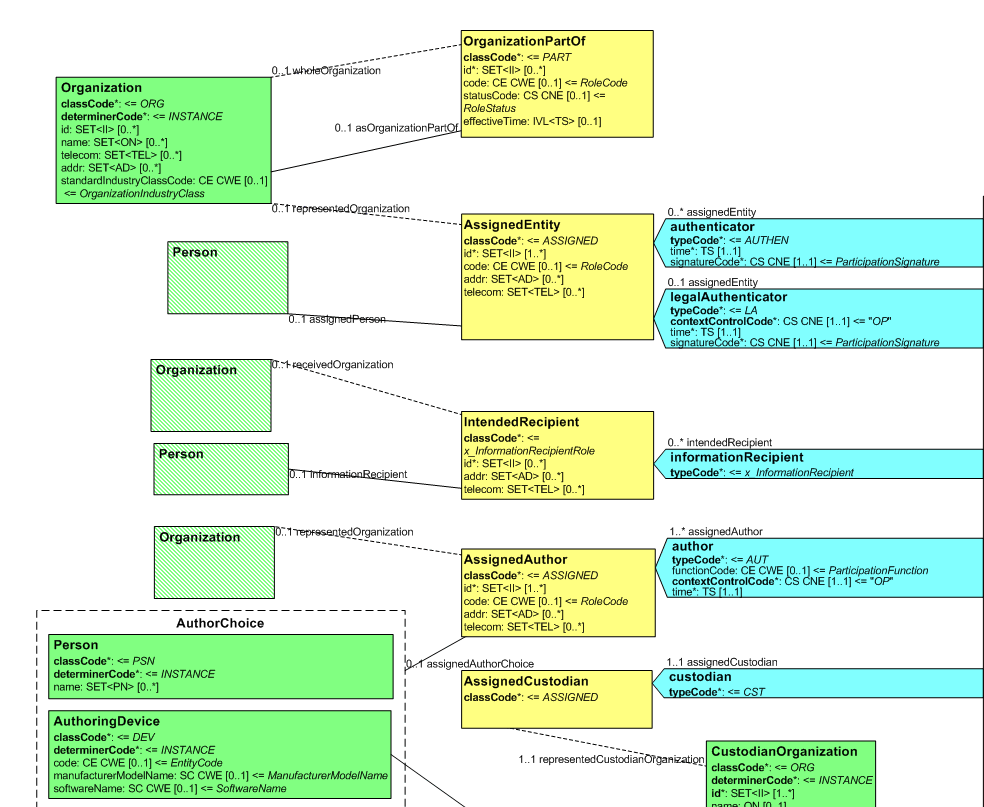
Here, the author and the authenticators must have an id, the organisation might, and the Person who acts as Author can’t. Wherever the CDA implementation guides use a CDA class that has an id, the id is specifically called out in the mappings, whether or not it is mandatory (it is noted when it’s mandatory):

The contents of the id is a root, and maybe an extension. The root can either be an OID or a UUID (GUID, for windows programmers). The comment that is used is a little opaque:
This is a technical identifier that is used for system purposes such as matching. If a suitable internal key is not available, a UUID may be used.
btw, I wrote those words, so I have the right to call them opaque ;-).
The basic idea here is that the identifier (root + extension if present) is unique for this object, and that you could use this to match this object against another copy of the same object that you saw in a previous document (or elsewhere in the current document). That’s what “used for system purposes such as matching” means.
Before I talk about the limitations and caveats around how you can – or can’t – match using this identifier, what do you put in the id element?
If you have a (e.g. database) integer/string primary key for the concept, then you use that. In this case, you either assign an OID to this clients copy of this table, or create a GUID that identifies it, and use this in the root. In the extension, you just put the primary key directly:
<id root="5c9ef1f6-1292-448f-9568-9c5166314613” extension=”141234”/>
That way, any time you represent the same concept in any CDA document, it gets the same identifier, and a destination system can be sure, for instance, that if the code for the type of problem has been changed, that the original problem has been edited, rather than a new problem created.
This does mean that you have to be careful to choose a primary key that does reflect this kind of behaviour – not one that would be re-used for a different concept if it becomes free, for instance.
If the source system uses GUIDs as the primary key, then that would be represented like this:
<id root="047fa6e4-5e12-46e5-932e-d52c5677af35” />
Ideally, the generator of the CDA document always has access to the primary source tables from which it is generated. But we don’t live in such an ideal world: many of the CDA documents are generated from some HL7 v2 or XML source document by middleware. And very often, the source documents simply don’t include the source primary key. Wherever possible, it’s best to get the source primary key added to the intermediate source from which the CDA document is generated, but sometimes it’s just not possible. In this case, the middleware can only assign a random GUID for the id:
<id root="0c2a809e-fca7-4452-86e6-dde2f54766bc” />
Note that you can’t tell the difference between the last two cases. So you can’t tell, when you look at an id element in a CDA document, whether the id element is the real primary key or not.
Also note that there’s space for more than id element - but you should only ever put one identifier there. Any other identifiers you have - MRNs, Provider identifiers, medication ids, etc - they go in the real world identifier.
Processing the id element – warnings and caveats
Ideally, the id element should be able to used for matching when content from the CDA documents is imported into an application. For instance, if a patient presents at a GP for the first time, all the patients documents would be downloaded from the pcEHR, and the system would collate the records based on the id elements so that only the latest version of each problem, medication, pathology report etc would end up in the system.
But there’s a series of caveats that mean that this is may not be a good idea:
- You can’t tell the difference between a real identifier, and a fake identifier made up to fill the space (unless the source system generating fake identifiers is not generating unique ones, you won’t get different records overwriting each other, but you will get identical records duplicating each other)
- It’s very hard to determine the correct chronological order for the records. While the CDA document timestamp is clear and unequivocal, it’s not clear that the records in the document necessarily share the same timestamp. In most cases, that’s probably the case - it’s the obvious thing to do, but there’s no rule that it has to be the case, and there’s no conformance checking around this
- The CDA documents are kind of snapshot anyway – if an existing record is deleted, it is simply omitted from later documents. So when collating records,idmatching won’t catch deleted records. In effect, you’ll have to rely on the latest document
- It’s not clear that you even want to match records like this in principle. In the PCEHR core, the underlying atomic data store does have the capacity to match records and overwrite earlier records with later copies. But when the consolidated views are generated out of that store, we don’t want the very latest information for an author or a problem etc to show as the content of earlier documents – we want what was shown in the original source document to appear in the view against that document. So the PCEHR data store never matches by theidelement
- Finally, a couple of RIM specific notes (ignore if you aren’t familiar with the RIM). RIM based processing engines might naturally associate a rule concerning immutable attributes that have consistent ids – that they can’t change, and it’s an error if an object with the same id but different immutable attributes is encountered. However, this is not the case – the quick explanation is that the value of the attribute (especially classCode/typeCode) may be constrained differently in different places. I’ll do a full explanation of this in a separate post if anyone wants
- And then, there’s Role.id
The RIM.id is a most slippery identifier. Note the definition from the RIM:
A unique identifier for the player Entity in this Role
That’s a little opaque: is that the identifier for the player when it plays this role, or the identifier for the player that is in this role? There’s a clarifying note:
The identifier of the Role identifies the Entity playing the role in that role
Only that doesn’t really clarify anything does it? I believe that the correct interpretation is the second: this is the identifier for the player – and that therefore the same role id may be encountered in multiple places for different roles where the same entity plays the different roles.
On these grounds, some of the CDA implementation guides say some variation of the following language:
When the author is also the ‘legalAuthenticator’ then ClinicalDocument/legalAuthenticator/assignedEntity/id SHALL be same as ‘ClinicalDocument/author/assignedAuthor/id
When the CDA implementation guides say this, then you can rely on this: the ids will match. That will be checked during the conformance process.
However, other than that, the ids probably aren’t going to be very useful in the near term. But you still have to fill them out where CDA requires them.