Do I need to render the CDA Narrative?
Feb 25, 2013In a couple of different CDA implementation contexts, the same question has come up: does an application receiving the CDA document need to render the document using the narrative, or can it simply ignore the narrative and process and display the structured data? If it can, under what conditions is that OK? As a background, CDA is a document that has a narrative presentation, a header that defines the clinical document, and which may include some structured data. By the original intent of CDA, it’s very much a document, and should be thought of as a standard way of doing a word document with embedded data, like this example from my usual CDA tutorial:
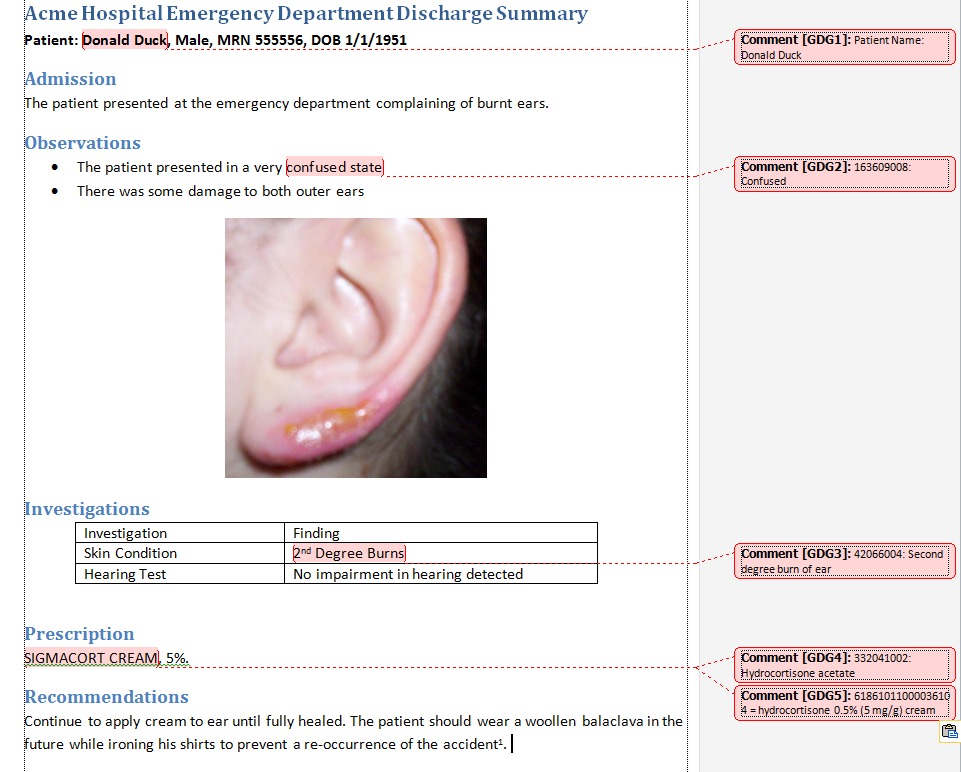
So ignoring the narrative is inherently a non-CDA type of thing to do. The anticipation in the CDA specification itself is that it’s alright to extract the data from the CDA document for other use, but once you’ve done that, it’s no longer part of the attested content of the document. The implication is that whenever you extract data, you should always retain a link to the source document, so that a user can see the original data in it’s context. For instance, the source system/clinician may have noted some qualifying information about the data in the narrative that is relevant to it’s interpretation.
However CDA is used in all sorts of contexts, some of them extremely data-centric. In practice, there are some uses where the document is pure human-written narrative, some where the CDA documents are pure data, and the constructed narrative is only a formality to satisfy the CDA specification itself, and others that are a mix, both in terms of implementations being more or less data driven, and different parts of the documents using different combinations. In some of these uses, it’s safe and even normal to ignore the narrative.
Given the diagram above, when is it ok to ignore the narrative? When:
- The authoring application populates the structured data completely and knows that the narrative says nothing additional
- The receiving application is able to correctly process all the structured data
- The receiving application is able to know the correct way to display the data
So it’s a collaborative effort between the author and the receiver.
Given the wide flexibility of the entries, and the data types they use, I believe that the only way that a receiving application can be sure that it is able to process all the structured data correctly, and know the correct way to present it, is where there is a tight implementation guide specifying exactly what data elements the CDA document can contain, how these are to be understood, and that there is strict and reliable conformance checking regime in place. The authoring application may know that the narrative is generated, or it may not. (the most common reason why it may not know is that the CDA document is being built by middle ware - a green CDA approach - and the narrative is an independent input of uncertain source).
So how can the rendering application know that the narrative doesn’t contain anything not in the structured data?
Entry.typeCode
The answer to this question is found in the typeCode on each entry. Here’s the relevant part of the CDA RMIM:

A section has narrative (the “text”), one or more entries which have typeCode attributes, and nested sections. The possible values for typeCode are:
| COMP (component) [default] | The associated entry is a component of the section. No semantic relationship is implied. |
| DRIV (is derived from) | The narrative was rendered from the CDA Entries, and contains no clinical content not derived from the entries. |
So you can tell, from the entries in the section, whether the narrative was generated from the entries, and doesn’t contain any other data.
The typeCode=”DRIV” attribute is a little difficult to interpret. Here’s some notes about how to understand this:
- If there’s no entries, and the section contains text, then the text is not generated from the entries (pretty obvious)
- If there’s one or more entries, and any of them claim typeCode=”DRIV”, then the narrative is entirely generated from the entries
- If some of the entries don’t have a type code, or the typeCode=”COMP”, then those entries aren’t represented in the narrative
- There’s no way to indicate that an entry is represented in the narrative unless you claim that the entire narrative for the section is generated
- The implication is that the entries relate to the section that contains them, though this is never explicitly stated
Here’s some example fragments:
<!-- a section with autogenerated text -->
<section>
<text>The patient has no problems</text>
<entry typeCode="DRIV">
<!-- an observation containing an assertion that there is no problems -->
</entry>
</section>
<!-- a section with human modified narrative -->
<section>
<text>
[a table of the patient's problems, built by application]
<!-- additional text added by a human: ->
<p>The patient also has renal failure</p>
</text>
<entry typeCode="DRIV">
<!-- an observation with a problem -->
</entry>
<entry typeCode="DRIV">
<!-- an observation with a problem -->
</entry>
</section>
<!-- a section with autogenerated text -->
<section>
<text>The patient has no problems</text>
<entry typeCode="DRIV">
<!-- an observation containing an assertion that there is no problems -->
</entry>
<entry>
<!-- an act with audit information that's not in the narrative -->
</entry>
</section>
So, in theory, you don’t need to render the narrative if all sections in the CDA document have no
Lloyd McKenzie has kindly contributed an XPath predicate for this test:
ClinicalDocument[component/structuredBody[not(descendant::
component/section[text and not(entry[@type='DRIV'])])]]
Practical Considerations
Note that I said that in theory this test works. However, in practice, there’s a number of problems associated with this:
- The CDA rules about typeCode are not very prominent (see section 4.3.4.2), and are often overlooked
- The CDA rules are not well documented, and even when documented more clearly, people find them very opaque
- For a variety of reasons, the division between sections isn’t as clear as everyone would like, and entries sometimes end up in more than one section narrative, or in the wrong section for a different reason
- Even amongst CDA implementation guide writers, the correct use and/or impact of typeCode=”DRIV” is easily overlooked. In fact, the implementation guides I have contributed to have been wrong on this in the past (NEHTA guides).
- Even if the CDA IG writers get it right, they may not anticipate the real world usage correctly, or they may provide an example which people copy without understanding (see the CCDA examples which include typeCode=”DRIV” on some examples and not others with no explanation)
What this means is that in practice, depending on typeCode=”DRIV” is unreliable due to poor compliance with the specification in this regard.
And in effect, then, you can only ignore the narrative and render the data if you’re really confident in the CDA implementation guide, and the conformance process associated with it’s implementation.
Explaining to the users what is going on
Ideally, an application would differentiate to the users between “displaying the data in the document” and “displaying the document”. Ideally, also, the users would actually understand the difference. But that’s not the world we live in. I think that this problem underlines the dangers of not rendering the narrative - you need to be really confident before you make that decision.