#FHIR DSTU2: Changing the Composition Resource
Sep 29, 2014While in Chicago, one of the decisions that we made was to refactor the Composition resource. Here’s the design in DSTU #1: 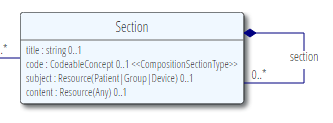
The design can be summarised in prose:
- A section has a title and a code that describe it, and it may have a section if the subject is different to the overall composition (documents that span multiple subjects are not that unusual)
- A section can contain other sections, or a resource that contains the content for the section
- The resource is allowed to be any kind of resource, but the most common kind is aList resource.
Observationally, almost all CDA sections are a list - medications, problems, diagnostic reports. There’s a few exceptions: a synopsis section, a care plan. But these are the minority.
There’s a major problem with this design, which revolves around the narrative/text dynamic in a document - what happens if there’s no entries, and only some narrative? Do you have to use a different resource type (other?) if you don’t have structured content (and actually, the way resources are defined pushes you in this direction, because many of them have required data elements, and you can’t use them if all you have is text (that’s a different issue for potential resolution elsewhere).
After a fairly long discussion about this problem, and consideration of a number of alternatives, the structured document working group decided to try this design: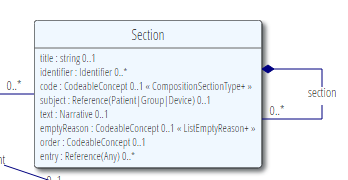
This design can be summarised in prose:
- A section has a title, a code, and an identifier that describe it. Note: the identifier should only be populated if it is persistent across different compositions (unlike CDA, where slippery ids are a source of confusion)
- A section can have narrative, and an empty reason, or sub-sections or entries (can’t have sub sections and entries, and must have a narrative unless it has sub-sections
- The narrative is the ‘attested content’ for the section (see CDA definition)
- Entries provide supporting data for the section narrative
- If there are no entries and no sub-sections, there can be an empty reason. This is for things like “No medications prescribed” or “None known”
- A code can be provided indicating what order the entries are in (the narrative order should match the order of the entries, but what is that order - chronological?)
Essentially, the relevant capabilities of the list resource have been conflated into the section.
This has the following advantages:
- All the attested narrative is inside a single resource
- The structure much more closely matches CDA (this will help with CCDA/FHIR implementation efforts that are ramping up)
- There is no ambiguity about what kind of resource to use
- There’s no confusion about the list snapshot mode - some of the list capabilities don’t make sense in a composition
There’s some potential downsides to this structure - particularly around conformance, and these are the subject of active development and testing, so implementers shouldn’t assume that this is the last word on the matter.