#FHIR Paradigms
Dec 21, 2017Many of the FHIR tutorials show this diagram: 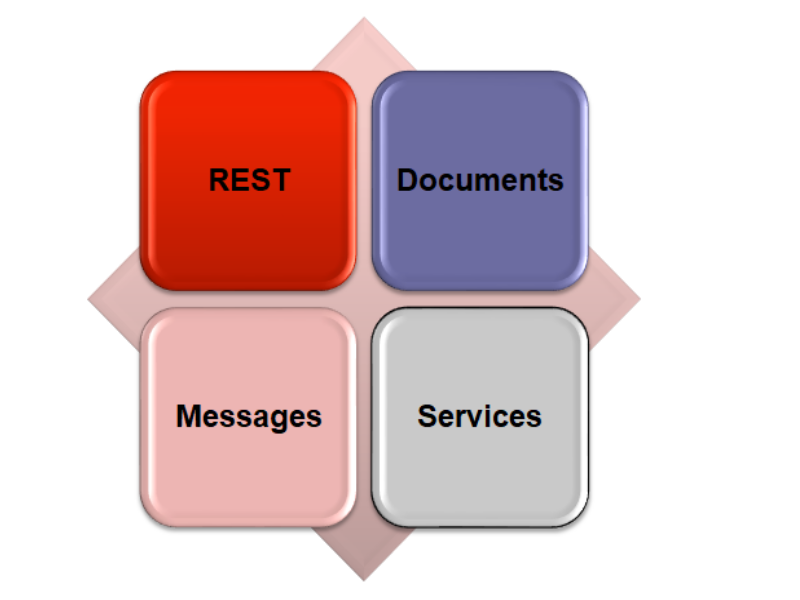
The goal of this diagram is to show that FHIR defines 3 different ways to exchange FHIR resources:
- Using the RESTful interface - the most high profile way to exchange data
- Packaging the resources in messages, and pushing them between systems (similar architecture as HL7 v2)
- Packaging the resources in documents, with a managed presentation (similar architecture as CDA)
Also, what this diagram is intending to show is that in addition to the 3 ways defined by the FHIR specification itself, there’s other ways to exchange resources. Since the most common alternative method is to use some enterprise web services framework (say. some kind of SOAPy thing) - we called it ‘services’.
But that’s misleading; a ‘service’ is some orchestration of exchange of FHIR resources, and most implementation projects build their services using some combination of RESTful interfaces, messages, and documents, along with other methods of transfer. And that’s a combination that the FHIR community thinks is perfectly valid. So calling the 4th ‘other’ category “services” is… misleading… to say the least.
However there’s something beyond that missing from this diagram. In the last year or so, the FHIR community has gradually become more focused on what is emerging as a distinct 4th paradigm: using persistent data stores of some kind or other to exchange data between systems. Classically, this is associated with analytics - but it doesn’t actually need to be. The typical pattern is:
- Create some kind of persistent store (can be an SQL database, a nosql db, a big data repository, an RDF triple store)
- Applications generating data commit resources to the store
- Applications using the data to the store find and retrieve data from the store at a later time
We haven’t really acknowledged this paradigm of exchange in the specification - but it’s what the RDF serialization is really about. And all the uses I’ve seen have one uniting characteristic: there’s a need to reconcile the data when it is committed, or later, to help with subsequent data analysis. There’s 2 kinds of reconciliation that matter:
- detecting, preventing or repairing duplicate records
- matching references (e.g. resolving URLs to their target identity in the database, and storing the native link)
One of the subjects I’d like to discuss in New Orleans next month is to gather the various disparate strands of work in the community around a ‘storage paradigm’ into a single coherent whole - if that’s possible. It’s something that we’ve been slow to take up, mainly because HL7 classically agrees to focus on the ‘interface’ and keep away from vendor design. But that’s happening in the community now has moved past this.
In particular, there’s really interesting and energetic work using new databases (or new features of old databases) to store FHIR resources directly in the database, and performing the analysis directly on the resources. Google presented some really interesting work around this at DevDays in Amsterdam a couple of weeks ago, and we’re working towards hosting a publicly usable example of this.
Clearly, we’ll need a new diagram to keep up with all these changes.